Counting with Algebird and Spark
Edward Sumitra
Summing Integers
1 + 2 + 3 + 4 + ... + 30(1 + 2) + (3 + 4) + ... + (28 + 29 + 30)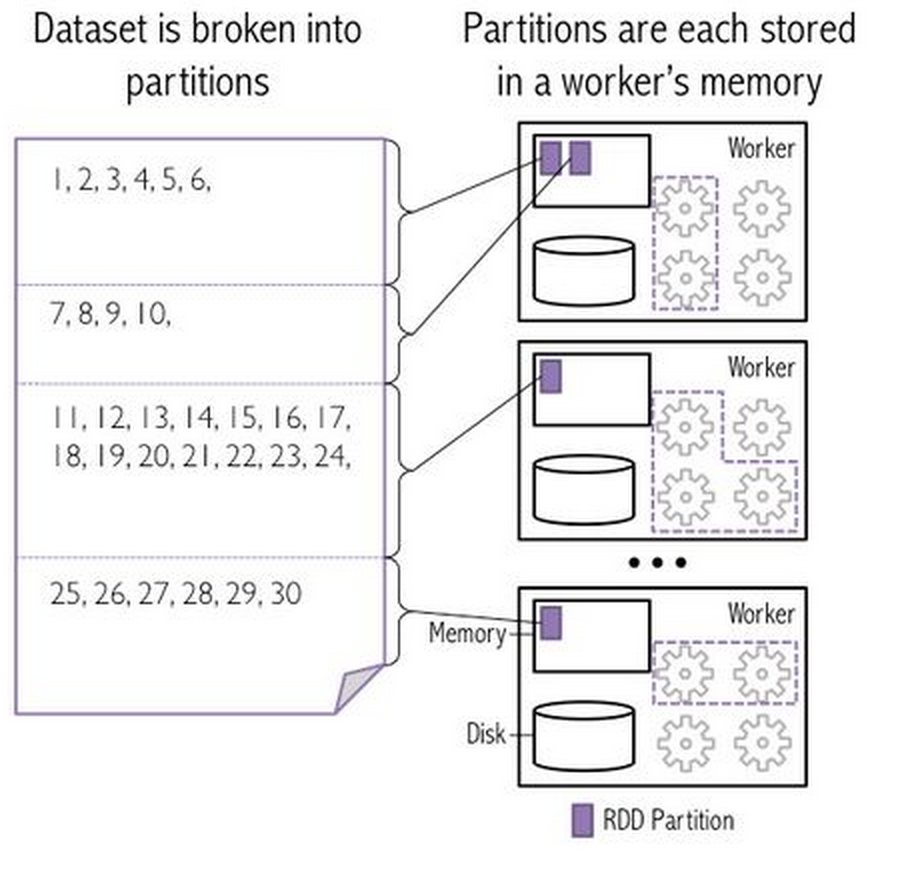
Algebraic properties of integers and addition
Closed: Int + Int = Int
Associative: a + (b +c) = (a +b) + c
Identity : a + 0 = a
(Z-*, +): Integers form a Monoid under addition
Monoid computations can be run efficiently on Spark
can be partitioned/parallelized
reduce in multiple stages
support "empty"/"zero" items
Abstract Algebra Redux
Semigroup (M,+)
- Closed
- Associative
Monoid (M, +)
- Closed
- Associative
- Identity
Group (M, +)
- Closed
- Associative
- Identity
- Inverse
Commutative

rdd
.map(toMonoid(_))
.reduce(_ + _)
Example - Average Monoid
Dataset - EdX data set: courses, students, days interacted with class, forum posts
Find the average number of days students interacted with courses in dataset
average = sum / count
average (0 , 1 , 2 , 3 , 4) != average (0 , 1 , 2) + average (3 , 4)
2
!=
1
+
3.5
MAverage(count, average)
a + b = ( a.count + b.count,
(a.count*a.average + b.count*b.average)/(a.count + b.count))
MAverage (0 , 1 , 2 , 3 , 4) = MAverage (0 , 1 , 2) + MAverage (3 , 4)
(5,2)
=
(3,1)
+
(2,3.5)
i.e., (MAverage, +) = Monoid
Identity = MAverage(0,0)
MAverage: associative, closed, identity
redefine "+" to be associative for MAverage
define a new type MAverage
Algebird from Twitter
An Abstract Algebra scala library for building aggregates like count, sum - i.e., "counting" problems
Easily define abstract algebraic types - semigroups, monoids, ...
Implementations for standard Scala types - Lists, Maps, Tuples
Aggregation with Spark can be expressed as a counting problem
rdd
.map(toMonoid(_))
.reduce(_ + _)
Implementations of - Count-Min-Sketch, Hyper-Log-Log, QTree
Algebird is not tied to Spark and can be used with vanilla Scala/Java collections
Probabilistic Counting - Hyper-Log-Log

import com.twitter.algebird._
import com.twitter.algebird.Operators._
import HyperLogLog._
def uniqueValues(sc:SparkContext,csvFile:String, colNum:Int):Long = {
val hll = new HyperLogLogMonoid(12) // ~ 1% probability of error with 2^12 bits
val rdd:RDD[Row] = SparkUtils.rddFromCSVFile(sc,csvFile, false)
val approxCount = rdd
.map {r => r(colNum).toString}
.map {c => hll(c.hashCode)} // HLL (defines zero and plus)
.reduce(_ + _)
approxCount.estimatedSize.toLong
}
Probabilistic Counting - Count Min Sketch
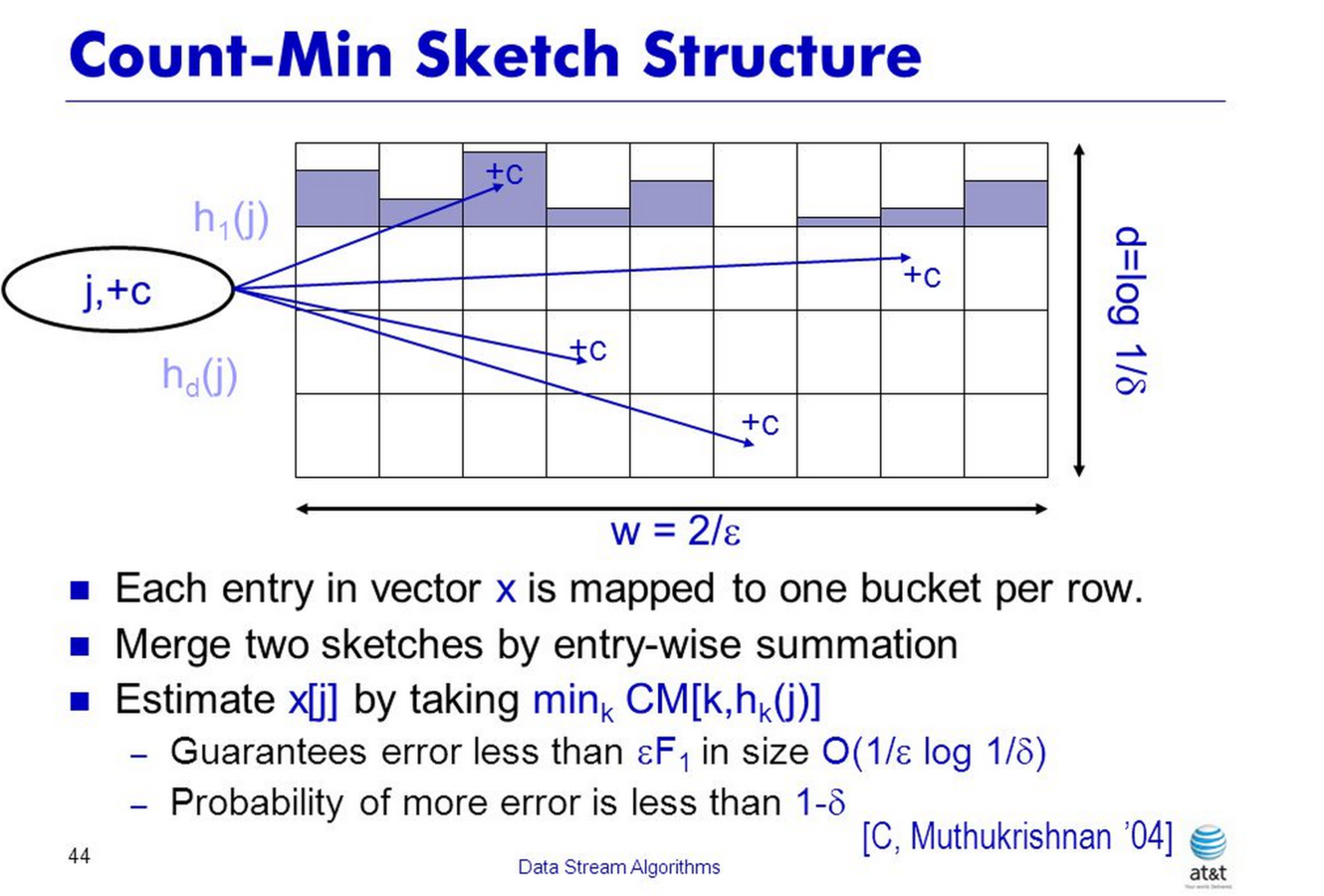
import com.twitter.algebird._
import com.twitter.algebird.Operators._
import com.twitter.algebird.CMSHasherImplicits._
def frequencyFunction(sc: SparkContext, csvFile: String, colNum: Int) : String => Long = {
val rdd:RDD[Row] = SparkUtils.rddFromCSVFile(sc,csvFile, false)
val cmsMonoid:CMSMonoid[String] = {
val eps = 0.001
val delta = 1E-10
val seed = 1
CMS.monoid[String](eps,delta,seed)
}
val cms = rdd
.map{r => r(colNum).toString}
.map{cmsMonoid.create(_)} // CMSItem monoid
.reduce(_ ++ _) // CMSInstance monoid
(x:String) => { cms.frequency(x).estimate }
}
Summary and Links
Structure calculations as monoids to run in parallel
Use Algebird to help build monoids
- https://github.com/twitter/algebird
Use Algebird monoid big-data counting algorithm implementations
- https://github.com/twitter/algebird/wiki/Learning-Algebird-Monoids-with-REPL